Problem Statement :
There are several use cases wherein a data flow process is dependent on multiple entities / files and the flow needs to be triggered only in presence of all files / entities.
So is there a way to trigger a Synapse /ADF pipeline flow at the arrival of N’th file rather than trigger the data flow process on arrival of each files.
Prerequisites :
- Azure Data Factory / Synapse Pipeline
Solution :
- A Schedule trigger in ADF / Synapse runs pipelines on a wall-clock schedule. So for our use case , we need to leverage Storage Event trigger as we need to trigger the Pipelines at the arrival of files.
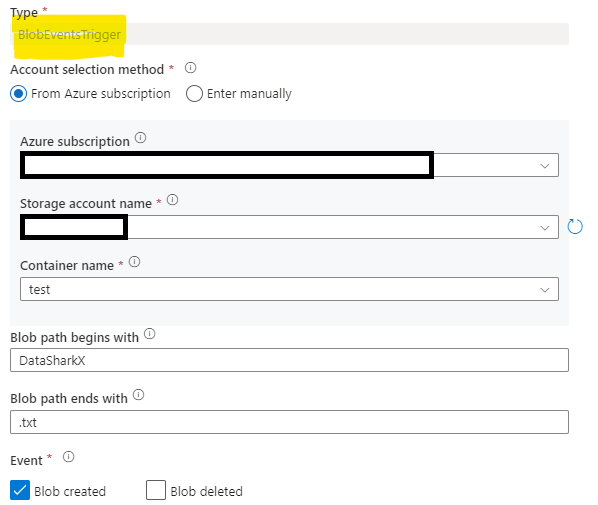
2. The above Blob Event trigger definition would ensure that the pipeline would be triggered every time a “txt” file extension is uploaded within a folder “DataSharkX” in the “test” Container.
So with our current use case of triggering the actual data flow process within the pipeline on arrival of N’th file and Blob Event trigger definition that ensures a pipeline is triggered every time a file is uploaded, we need to have a conditional logic created that would ensure that overall data flow process in triggered at the N’th file arrival even though the pipeline is triggered on every file arrival.
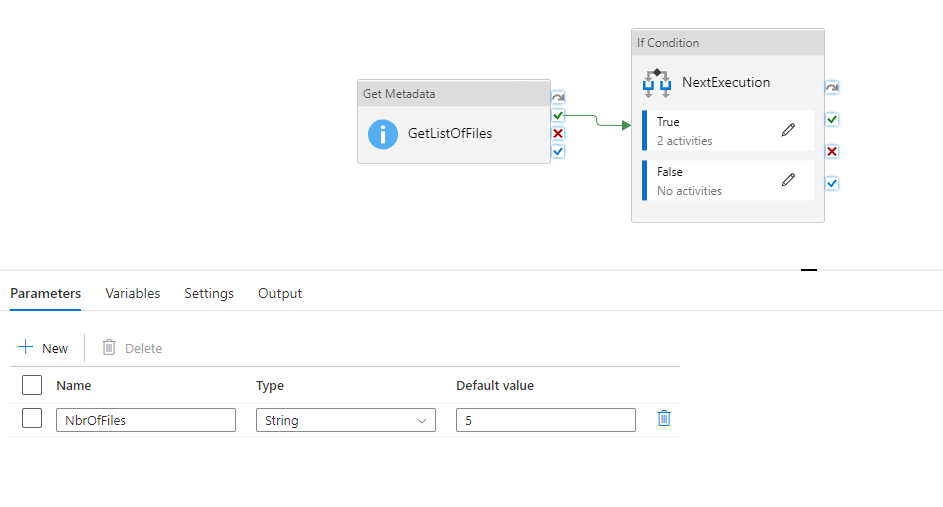
3.A Parameter called “NbrOfFiles” needs to be created that would maintain the value w.r.t the count of files (N’th) post which the pipeline needs to be triggered.
4. The first task within the pipeline would be to get the count of the files in the blob container which one can accomplish via the Get Metadata activity with argument as Child Items and the dataset mapping to the event trigger path.

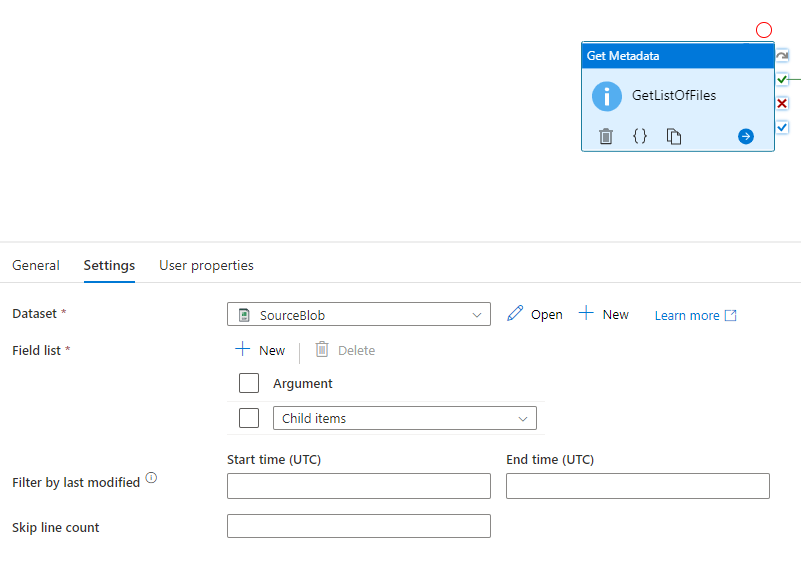
4. The output of Get Metadata activity “Child items” would be an array and to get the number of files within the blob path folder , we would need to get the count of the array output.
@length(activity('Get Metadata activity').output.childItems)5. The next step would be to compare the above output with the Parameter value (N’th file) via an IF activity and in case if the value matches, proceed with the actual flow else ignore the current pipeline trigger and exit the pipeline.
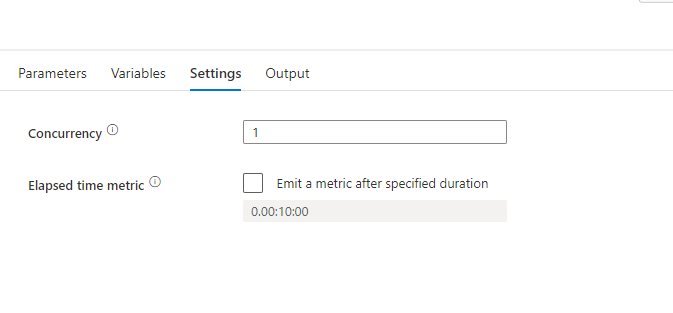
6. There can be scenarios wherein multiple files are uploaded in the blob at the same time which in turn creates multiple triggers of the same pipeline simultaneously. So in order to avoid the parallel execution, we need to Set the Concurrency property of the pipeline to ‘1’.
7. On Arrival of N’th file and post execution of all necessary activities of the data flow process within IF activity, we need to delete/archive all the files at the source path via Delete activity.
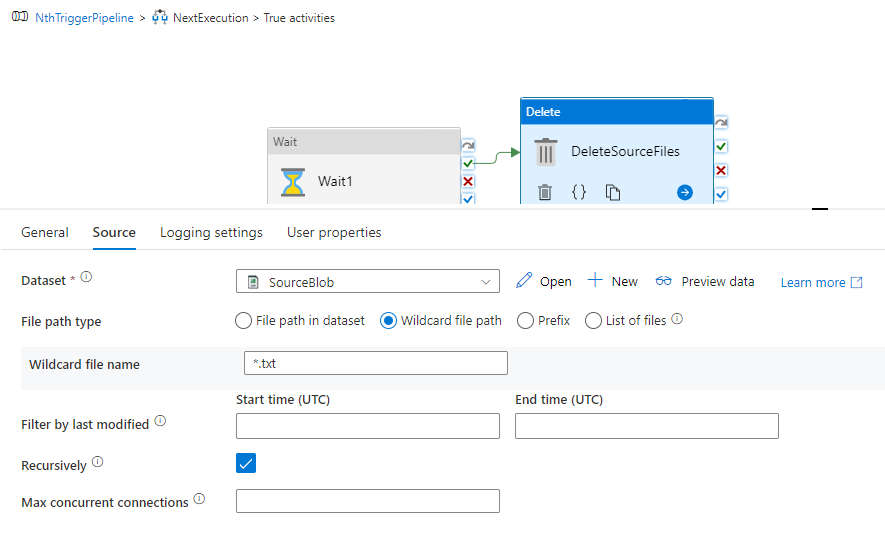
8. The Delete activity would delete all files within the folder which in turn would also delete the folder and in case if there are multiple event triggers originating at the same time and with concurrency set to 1, the next iteration of execution would fail with the below error:

9. In order to avoid the above failure, Upload a dummy file within the folder ;of an extension other than your file extension and use wildcard file name property to delete just the files of the needed file extension.

In our case the files are Text files, hence the wildcard file name property within Delete activity is *.txt and the Dummy file uploaded is an xlsx file.
10. In case if there are use cases wherein we need to process all the files arriving simultaneously in a singular flow i.e the NbrOfFiles Parameter value is unknown or blank , the above approach itself would work. So with a slight modification in the IF activity condition, we would be able to achieve the N’th file or this scenario.
a) If the Parameter is blank ,we would need to exclude the Dummy file from the count and check whether the count of Child items is greater than 0 {This is w.r.t scenarios wherein in case of multiple files arriving at same time and with concurrency set as 1, the 1st iteration would delete all files except the dummy file and for the successive iterations, we should ideally skip/terminate the pipeline}
@not(equals(string(length(activity('GetListOfFiles').output.childItems)),'1'))b) If the Parameter has a contain w.r.t Nth value, we would need to add 1 to the parameter count to include the Dummy file count as a part of source path folder file count
@equals(string(length(activity('GetListOfFiles').output.childItems)),string(add(int(pipeline().parameters.NbrOfFiles),1)))Overall expression to handle both scenarios:
@{if(equals(coalesce(pipeline().parameters.NbrOfFiles,''),''),not(equals(string(length(activity('GetListOfFiles').output.childItems)),'1')),equals(string(length(activity('GetListOfFiles').output.childItems)),string(add(int(pipeline().parameters.NbrOfFiles),1))))}
The JSON for the above Event based framework is available at this GitHub location.
Pipeline Execution output:
Scenario 1 : Wait1 activity should trigger on arrival of 5 Text files
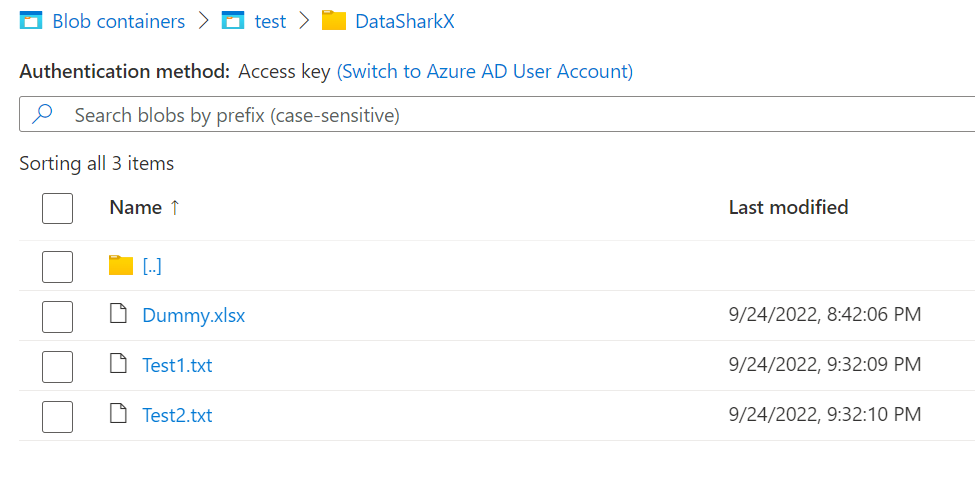
case 1: Arrival of 2 Text files simultaneously
Input:
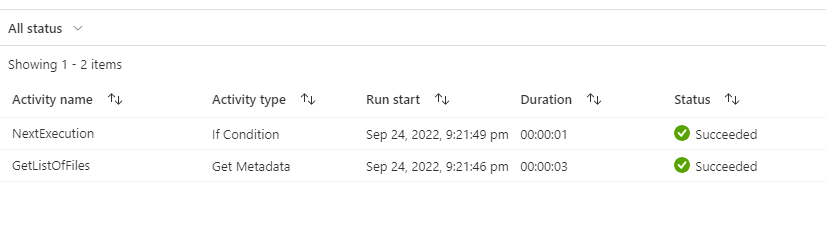
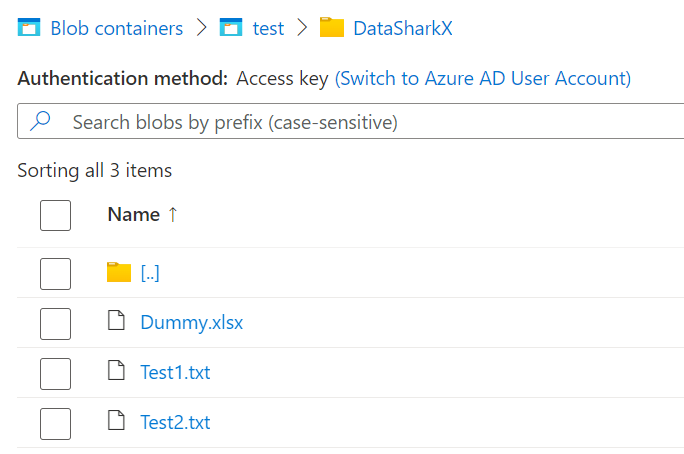
Output :
2 Event triggers but in sequential flows with the same results


case 2: Arrival of remaining 3 Text files simultaneously
Input:
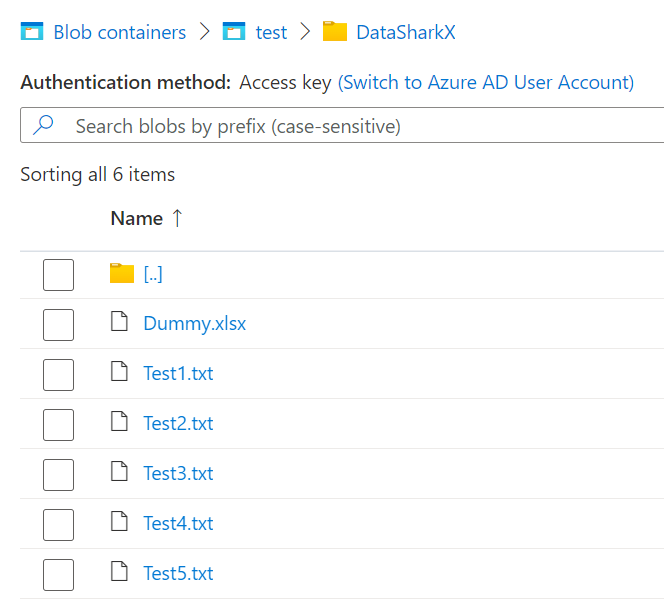
Output :
3 Event triggers but in sequential flows

1st Execution output:

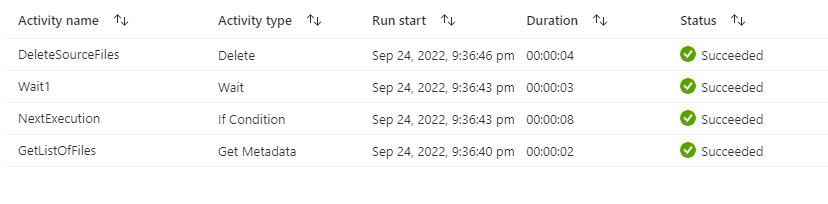

For all remaining iterations :
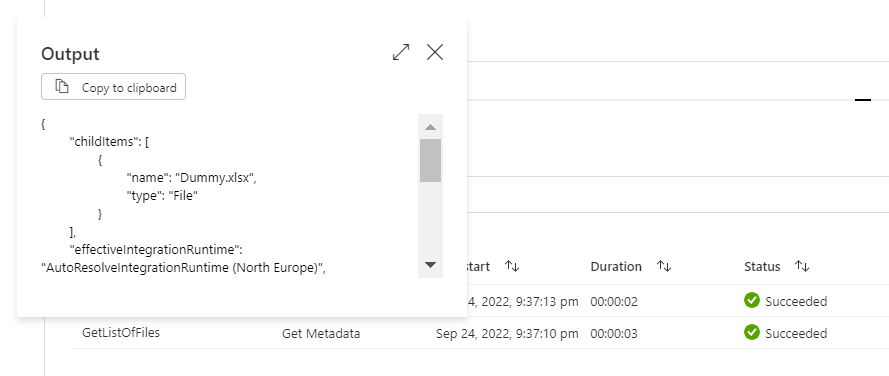
Scenario 2 : Wait1 activity should trigger only on 1st event trigger and process all files on arrival of multiple files simultaneously and the subsequent trigger iterations should gracefully exit the pipelines with no actions
This would follow output similar to Case 2 in Scenario 1.
Note: The Parameter “NbrOfFiles” is made blank for this scenario test case.
