Problem Statement :
As of 30th Aug,2022 ; Azure data factory / Synapse pipeline do not have an out of box functionality to get the list of all sheets within an excel file. In case if there is a need to load/convert all sheets within an excel into some sink, one has to maintain a list of all Sheets manually and iterate it over a for activity but in case if the sheet list are not fixed, one has to write a custom logic in some other Azure Offering and leverage it to iterate within ADF/Synapse pipeline.
Is there a way to avoid the custom logic creation and leverage out of box ADF/ Synapse pipeline functionality to dynamically iterate overall all excel sheets and map it to corresponding sink.
Prerequisites :
- Azure Data Factory / Synapse Pipeline
Solution :
- In my previous blog, Iterating across all Excel Sheets dynamically and Converting into CSV files via Azure Data factory / Synapse Pipeline ; we leverage Until activity which in turn processes the Excel Sheets Sequentially but in case if there is a need for parallel processing we need to follow the route of ForEach activity.
- The below hack for Parallel processing by leveraging ForEach activity was in turn thought across by Martin Jaffer, a MSFT employee which I am formalizing below.
- In this pipeline development as well, we work on the aspect of iterating by Sheet Index/Ordinal rather than by Sheet Name.
- In this Process we deliberately fail a Get Meta data activity ( with an assumption of Sheet Index being grater than the actual Sheet count in Excel ) we can find out how many sheets actually exists and start iterating from there onwards.
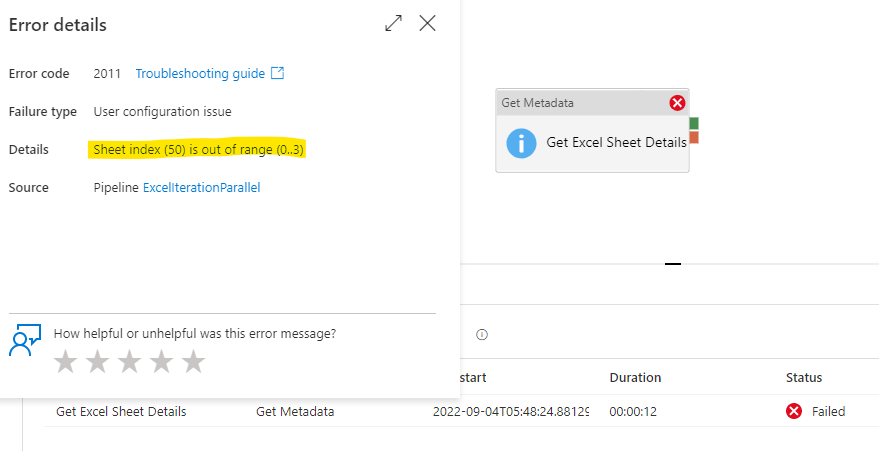
Assumption : The Sheet Index value is inputted as 50 (with the assumption that the current Excel file would never contain more than 49 sheets )

We need to leverage the Structure filed list because that actually needs to look at the sheet, as opposed to Exists which only check for the presence of the file (which would not fail and we need the activity to fail to get the Error Message with the actual Sheet Index value)
5. Now the next aspect would be to Parse the error message to extract the max Sheet Index value (i.e 3 in the current case) based on the below expression
@replace(split(activity('Get Excel Sheet Details').error.message,'..')[1],')','')6. The next step would be to create an Array range for us to iterate over via the below expression :
@range(0,add(1,int(variables('Max Sheet Index'))))The range(0,2) function yields [0,1] . This is because the second value is number of elements, so we actually want to add 1 to the number.
7. The last stage would be leverage the ForEach activity to iterate over the Array range created and do the necessary activities within it.

8. Output Logs of Pipeline execution :
4 CSV files got generated each with SheetIndex number appended (0,1,2,3 mapping to the 4 different sheets within Excel ABC,DEF,GHI & JKL)

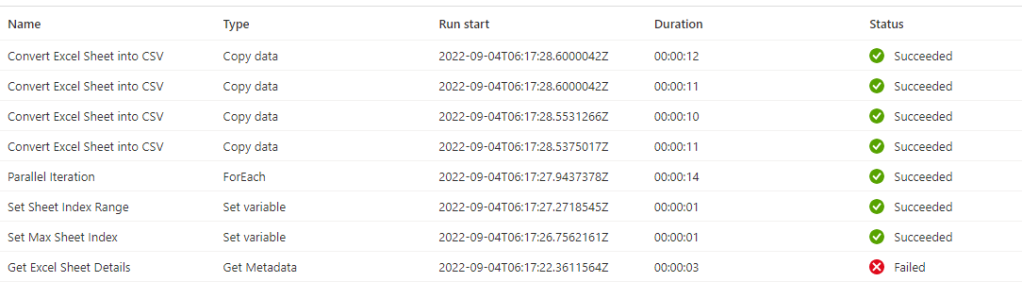
Note : The Pipeline iteration would be success due to the Error handling scenario even if one of the activity has failed.
For more details, please refer this Blog.

The JSON for the above Excel Sheet iteration framework is available at this GitHub location.
Note : In this method we go would some assumption that the actual Sheet Index within the Excel would be lower than the Sheet Index value passed in the Get Meta data activity and with the thought that the Error message format within the pipelines would remain same (In case if the Error message format changes, we might need to update the parsing logic accordingly)
