Problem Statement :
As of 17th Feb, 2024 MSFT Fabric Data Pipeline has a limitation of only 40 activity per pipeline.
Because of this limitation, managing logging framework by avoiding redundant activities and reusing the existing activities becomes a priority task.
Below are 2 scenarios wherein we are leveraging the same logic across multiple instances (same Set Variable activity / {Same logical activities}) and increasing the number of activities in a pipeline.
a) Serial Frame work :

b) Parallel Frame work :

So how can we avoid such redundant activities and still achieve the same result as expected.
Prerequisites :
- MSFT Fabric Data Pipeline
Solution :
MSFT Fabric Data Pipeline enables a user to take different flow paths upon outcomes of previous activities. One can branch and chain activities by creating a dependency between them and the dependency conditions.
There are four conditional paths:
- On Success
- On Failure
- On Completion
- On Skip
Those familiar with SSIS tool might link this with the SSIS Precedence Constraints but there are major differences between both as to SSIS Precedence Constraints :
a) One can have multiple constraints as a logical OR or a logical AND
b) One can add expressions to determine the flow lineage.
But in Case of MSFT Fabric Data Pipeline , all Activity dependencies map to Logical AND.
With the proper usage of ‘On Skip’ and ‘On Completion’ dependency conditions, it is possible to route failure in different points of the pipeline to a same activity which in turn reduces the need of redundant activities.
Below are the basic principles that need to be followed :
Multiple dependencies with the same source are OR’ed together.
Multiple dependencies with different sources are AND’ed together.
Together this looks like (Act_3fails OR Act_3Skipped) AND (Act_2Completes OR Act_2skipped)
Serial Frame work :
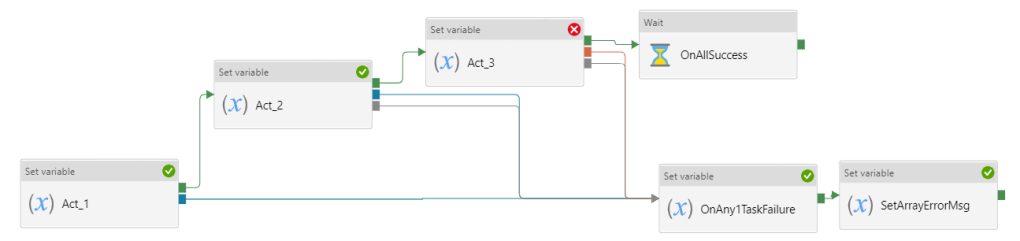
The JSON for the above Serial framework is available at this GitHub location.
For activities in series ( not parallel ), failure is not the only case to handle. For a sequence of activities linked my success dependencies, when an early activity fails, later activities are skipped. When a late activity fails, the early activities succeeded. Thus, to handle both cases, you must handle success, failure, and skipped.
Completion is the opposite of skipped. Completion encompasses both success and failure.
Parallel Frame work :
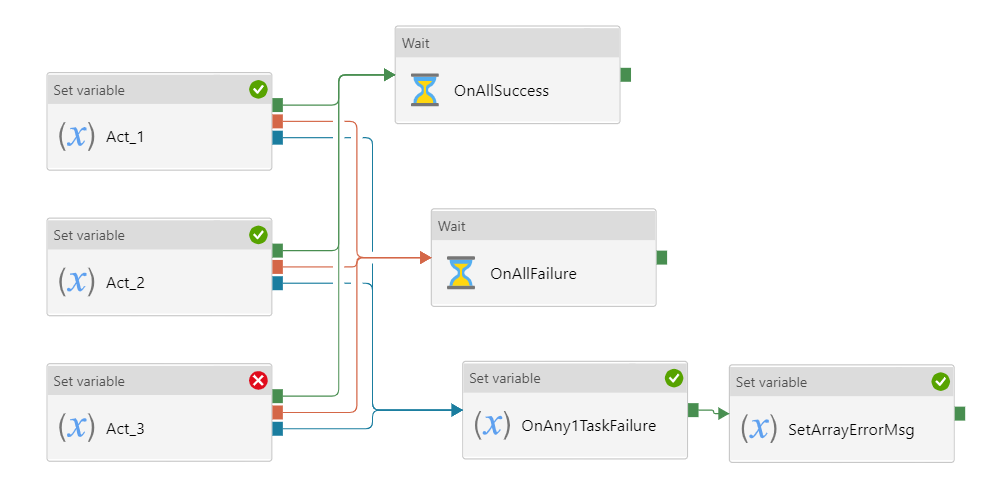
The JSON for the above Parallel framework is available at this GitHub location.
As seen above, the OnAllSuccess Wait and OnAllFailure Wait activity would be triggered when all source lookup activities are Success and Failures accordingly.
So for any framework , in order to capture the error message for any activity ; we need to leverage the below expression to concat all error messages if any.
| @concat(activity(‘Act_1’).error?.message,’^|’, activity(‘Act_2’)?.error?.message,’^|’,activity(‘Act_3’)?.error?.message) |
**When the activity has not failed, it cannot make an error. The ?. makes a thing null-safe.
In MSFT Fabric Data Pipeline, Pipeline success and failure are defined as following :
1) Evaluate outcome for all leaf activities. If a leaf activity was skipped, evaluate its parent activity instead.
2) Pipeline is a success if and only if all leaves succeed.
So to summarize , Overall pipeline success/failure is not determined by the failure of a single activity. A pipeline fails when either:
1) The last activity in a pipeline fails
2) An activity (X) has an on-success dependent activity (Y), and that activity (Y) is not run.
The below documentation would guide through different scenarios of conditional paths and the relative pipeline outcomes for MSFT Fabric Data Pipeline.
